How large-scale systems learned that reactive cache policies fail under burst-driven demand
Introduction
Over the last decade, content delivery has reached a scale where many long-standing engineering assumptions no longer hold. Systems that once worked reliably under moderate load now show fragile behavior when traffic becomes highly concentrated, globally synchronized, or rapidly shifting.
Content Delivery Networks, or CDNs, sit at the center of this change. Their role is simple in principle, to move data closer to users in order to reduce latency and backend load. In practice, this role has become increasingly complex as demand patterns have grown less predictable and more burst-driven.
Caching is the mechanism through which CDNs achieve scale. Yet many of the caching strategies still in use today were designed for a different era of traffic. As platforms have grown, these strategies have revealed structural limits that cannot be addressed through tuning alone.
The limits of rule-based caching
What traditional caching optimizes for
Most caching systems still rely on variants of a small set of rules, such as Least Recently Used, Least Frequently Used, or fixed expiration through Time-To-Live values. These approaches optimize for simplicity and local efficiency. They assume that recent access is a reasonable proxy for near-term demand and that traffic evolves gradually.
For many years, these assumptions were serviceable. They are also deeply embedded in caching infrastructure, tooling, and operational practice.
Why those assumptions break under modern load
At scale, traffic does not evolve gradually. It shifts abruptly, often in coordinated ways. A single piece of content can transition from cold to globally hot in minutes. When that happens, reactive cache policies lag demand rather than shaping it.
The result is not merely lower cache hit rates. It is synchronized pressure on backend systems, created precisely when those systems are least prepared to absorb it. This behavior is not an anomaly. It is a predictable outcome of rule-based caching under burst-driven demand.
What large-scale systems have already taught us
Failures that exposed the model, not the implementation
Several large platforms have publicly documented incidents where caching behavior contributed to instability at scale.
Meta engineers have described request surges that occur when cached content expires or becomes invalid across many clients at once. Netflix has written about the operational cost of cache misses when they occur at volume, particularly when backend services are forced to absorb bursts they were not designed to handle. Roblox’s multi-day outage in 2021 illustrated how extreme load and recovery failures can cascade across shared infrastructure. AWS’s introduction of CloudFront Origin Shield reflects similar lessons learned while operating at global scale.
These events differ in cause and context, but they point to the same underlying limitation. Cache decisions made purely in reaction to past access patterns leave systems exposed when demand changes faster than cache state.
A repeating structural pattern
Across these systems, the same pattern appears. Reactive cache policies allow demand spikes to propagate inward, concentrating load on backend services. Once this happens, recovery itself becomes difficult, because the system remains under pressure while attempting to stabilize.
This is not a question of better tuning or stronger hardware. It is a mismatch between how decisions are made and how demand actually behaves.
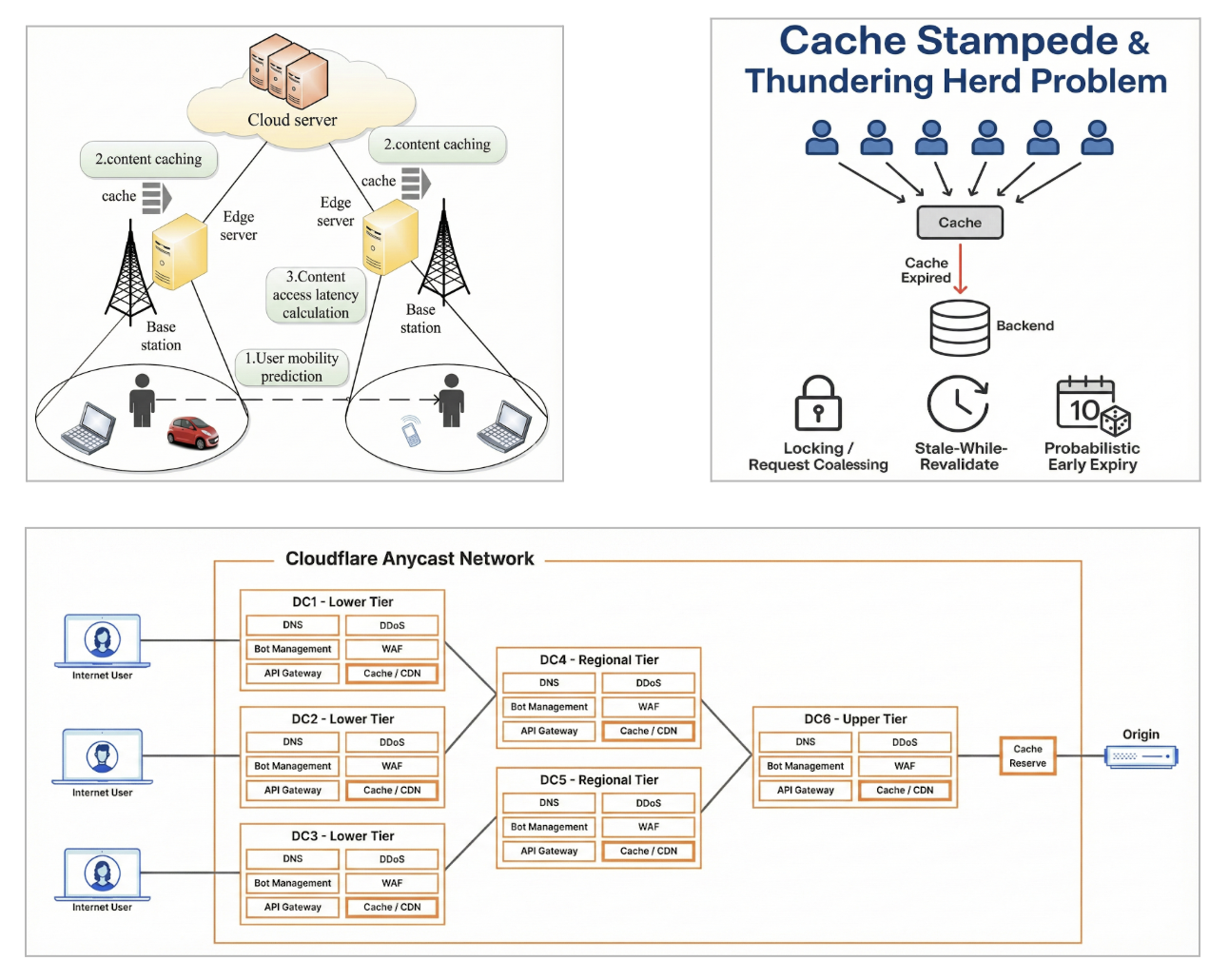
Sample Figures: Reactive cache policies respond only after demand arrives, while predictive systems position content ahead of demand to reduce synchronized backend load.
Why incremental fixes failed to close the gap
In response to these issues, platforms introduced mitigations. Expiration windows were adjusted. Safeguards were added. Internal tooling evolved. These changes reduced risk in specific cases but did not remove the underlying vulnerability.
Most fixes remained manual and situational. They relied on engineers anticipating future demand and encoding that anticipation into static rules. As systems grew larger and more interconnected, this approach became increasingly brittle.
What was missing was not another rule, but a different way of making decisions.
Reframing caching as a predictive system
The signals already exist
Modern CDNs observe a rich set of signals, including request rates, burst patterns, geographic distribution, device characteristics, and content churn. These signals change continuously and often faster than human operators can respond.
Static thresholds cannot capture this complexity. The data itself already describes emerging demand.
The decisions that matter
At scale, caching is a continuous decision problem. Systems must decide what to place, where to place it, how long to retain it, and when to remove it. These decisions interact across cache tiers and over time.
Treating them as independent configuration choices ignores their systemic nature.
Where machine learning adds value
Machine learning becomes useful not because it is complex, but because it can estimate near-term demand under uncertainty. Models can identify when access patterns are shifting and when content is likely to become highly requested before the first wave of cache misses occurs.
In this role, AI does not replace system control. It provides foresight. The system still enforces constraints, protects backend services, and manages risk. Prediction informs action rather than dictating it.
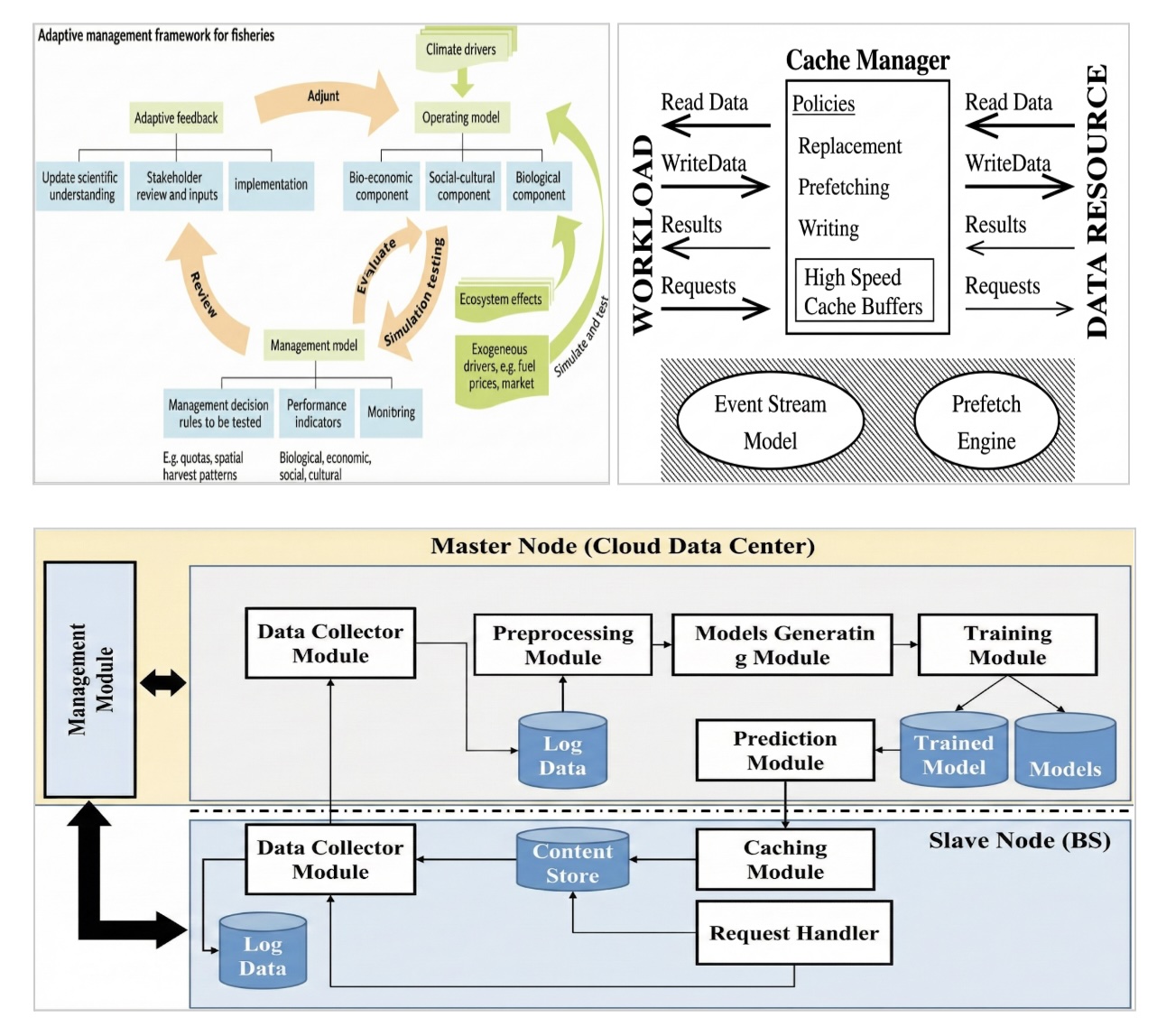
Sample Figures: Adaptive caching systems use continuous feedback to adjust placement and retention decisions as traffic patterns change.
Predictive caching as a control problem
When caching decisions are guided by expected future usage, system behavior changes. Content is positioned ahead of demand. Cache state evolves with traffic rather than trailing it. Backend systems experience smoother load profiles, even during bursts.
Adaptive caching treats cache behavior as a feedback loop. Decisions are revisited continuously as signals change. Manual tuning gives way to ongoing adjustment, bounded by operational guardrails.
This represents a shift from configuration to control.
Mapping known failure modes to adaptive behavior
The relationship between past failures and predictive systems is straightforward:
Synchronized cache misses are mitigated by proactive placement
Backend overload is reduced by keeping high-demand content closer to users
Dynamic content benefits from demand-aware retention
Operational fragility decreases as manual tuning is reduced
These are not minor optimizations. They are responses to well-observed system behavior.
Alignment with how the industry is evolving
Research over the past several years has increasingly focused on adaptive and learning-based caching. Production systems now expose mechanisms designed to protect origin services and respond dynamically to traffic changes.
While implementations vary, the direction is consistent. Large-scale systems are moving away from static rules toward decision frameworks that anticipate demand.
Why this matters at scale
Caching failures do not only affect latency. They affect availability, cost, and user trust. At global scale, inefficiencies compound quickly, increasing infrastructure spend and energy use.
As digital services continue to grow, predictive and adaptive caching is no longer an advanced feature. It is a baseline requirement for operating sustainably under modern traffic conditions.
Conclusion
Rule-based caching systems were built for a world where demand was stable and predictable. That world no longer exists. Over time, large platforms have repeatedly encountered the same limitation, reactive cache decisions arrive too late to protect backend systems under burst-driven load.
The industry’s gradual move toward predictive, learning-based caching reflects this reality. Treating caching as an adaptive control system rather than a static policy set is not a trend. It is a response to how large-scale systems actually behave.
References
Roblox, Roblox Return to Service 10/28–10/31 2021
Engineering at Meta, More Details on Today’s Outage
Netflix TechBlog, Driving Content Delivery Efficiency Through Classifying Cache Misses
Amazon Web Services, Using Amazon CloudFront Origin Shield
Chen et al., Darwin: Flexible Learning-Based CDN Caching, ACM SIGCOMM 2023
Tang et al., RIPQ: Advanced Photo Caching on Flash for Facebook, USENIX FAST 2015
Akamai Technologies, Predictive Prefetching, Technical Documentation
Disclosure
The author has worked on system architectures related to large-scale content delivery and caching.



